尝试 1:使用 SQLAlchemy 的 Dynamic Relationship Loaders 功能: #
class BasicInfo(Base):
__tablename__ = "basic_info"
day_infos = relationship(
"DayInfo", order_by="desc(DayInfo.date)", lazy="dynamic"
)
class DayInfo(Base):
__tablename__ = "day_info"
code = Column(String(8), ForeignKey("basic_info.code"), primary_key=True)并在读取中使用 limit 控制读取的个数。处理 3 天的数据查找指定条件,用时约 1 分钟。
尝试 2:一次性读取所有的记录 #
按照尝试 1 的做法数据库请求的个数会很多,数千次请求不会很快。如果改用所有数据合并到一次请求当中,则大大加快。用时达到 8 秒。
问题 1:启动时间 #
由于需要导入大量的库,启动时间约有 4 秒钟,不容乐观。
使用 PYTHONPROFILEIMPORTTIME=1 运行,并将 stderr 导出至文件,使用 tuna 查看,发现大头是 pandas 和 SQLAlchemy。由于 pandas 并不是每次运行都需要使用,故将其从 top level import 挪到的相应的函数中。时间减少了 2 秒。
此时用时达到 6 秒。
尝试 3:使用 List Comprehension 运行匹配算法 #
时间几乎没有变化。后来知道是匹配算法本来运行时间就短的原因。
尝试 4:使用 SQLAlchemy 自带的分页功能读取数据 #
for data in session.execute(
session.query(BasicInfo, DayInfo)
.join(BasicInfo.day_infos)
.where(DayInfo.date > date_after)
.execution_options(yield_per=1000)
).partitions():时间并没有显著变化,但是内存的占用从大约 9% 降至 2%。可以肯定是 Python 的对象数量减少带来的。
尝试 5:更换 Python 的 MySQL 连接库 #
使用 python -m cProfile -o program.prof -m myprog ,再使用 snakeviz 可视化,发现很多时间被用在了 parse string, int 等上。而且使用 top 命令也可以看到 CPU 占满了一个核。将 PyMySQL 更换为 mysqlclient 后,处理 40 天数据从 22 秒降至 12 到 13 秒。
问题 2:分页 #
由于股票数据很多,尽管尝试 4 中使用了分页,但是在 MySQL 中,数据仍是一次读取。
参考了网上的资料:
- https://www.xarg.org/2011/10/optimized-pagination-using-mysql/
- https://qsli.github.io/2016/09/30/pagination/PPC2009_mysql_pagination.pdf
看到应该结合所选的条件进行分页而不是暴力地 LIMIT OFFSET. 如:
SELECT day_info.*, basic_info.data FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE DATE > '2021-03-01'
AND (
basic_info.code > 'sh600011'
OR (basic_info.code='sh600011' AND day_info.date > '2021-03-03')
)
LIMIT 30尝试 6:不使用 SQLAlchemy #
进一步 profile 看到有很多运行时间是花在 SQLAlchemy 上的。直接跳过 ORM 层操作,时间减少了约 1 秒(可能就是不 import SQLAlchemy 带来的),但是在运行时间中,CPU 占用比率((user + sys)/real) 从 96% 降至 50% - 60%。这意味着性能瓶颈由原来的 CPU 转化为 CPU 和 IO
问题 3:Query Time #
过程中发现 MariaDB 突然表现出了缓存功能,再次运行后 IO 时间显著减小至可以忽略。所以 MySQL 的 query 速度还有很大的优化空间。
使用
SHOW GlOBAL VARIABLES LIKE 'slow%log%'发现并没有开启对慢查询的日志,使用以下命令开启:
SET GLOBAL slow_query_log='on';
SET GLOBAL slow_query_log_file='/var/log/mysql/sql-slow.log';
SET GLOBAL long_query_time = 1;查阅日志可以看到,一条一万数据的 select 花了 7 秒钟才完成。
Query_time: 6.917748 Lock_time: 0.000308 Rows_sent: 10000 Rows_examined: 799为方便调试性能,需要关闭缓存功能,可使用 SELECT SQL_NO_CACHE ... 实现。
如问题 2 中的 query:
SELECT sql_no_cache day_info.*, basic_info.data
FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE DATE > '2021-01-25' AND (
basic_info.code > 'specificode' OR (
basic_info.code='specificode' AND day_info.date > '2021-02-09'
)
)
LIMIT 5000;单独运行需要 3 秒钟。但是如果拆成 2 个:
SELECT sql_no_cache day_info.*, basic_info.data
FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE DATE > '2021-01-25' AND basic_info.code > 'specificode'
LIMIT 5000;SELECT sql_no_cache day_info.*, basic_info.data
FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE basic_info.code='specificode' AND day_info.date > '2021-02-09';则半秒钟内即可完成。
有没有将两个合成一个但又不影响性能的方法呢?是有的。使用 UNION 合并两个 query,并注意要用 UNION ALL 跳过去重步骤,并用括号第把二个语句括起来。如果不使用括号,则 LIMIT 将被识别为整个大语句的,严重影响速度。
SELECT SQL_NO_CACHE day_info.*, basic_info.data
FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE basic_info.code='specificode' AND day_info.date > '2021-02-09'
UNION ALL
(
SELECT day_info.*, basic_info.data
FROM basic_info
JOIN day_info ON basic_info.code=day_info.code
WHERE DATE > '2021-01-25' AND (
basic_info.code > 'specificode'
)
LIMIT 5000
);处理 40 天数据降至 7 秒。
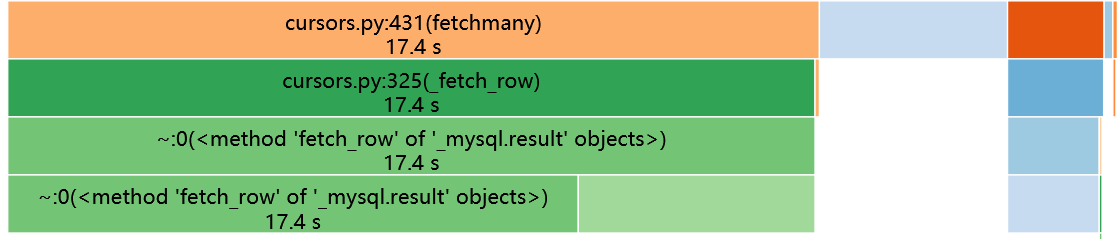
尝试 7:use_result vs store_result
#
在 mysqlclient 中,默认的 cursor 类在底层使用 store_result,即将每一次查询的结果一股脑存下来备用。相比之下 use_result 就人性化很多,先放在 server 里有需要再取,也符合 fetchmany 的初衷。
使用默认 Cursor 类的 profile 结果:

使用 SSCursor 类的 profile 结果(橘色那块是 execute,剩下那块是另一个与 SQL 无关的函数,也就是上图较深灰的部分):